참고 블로그
https://malwareanalysis.tistory.com/566
https://hanhorang31.github.io/post/pkos2-4-monitoring/
[PKOS] Thanos를 통한 고가용성 모니터링(프로메테우스) 시스템 구축하기 | HanHoRang Tech Blog
고가용성 모니터링 시스템 구축(프로메테우스, 타노스)
hanhorang31.github.io
pkos 스터디 4주차 - 메트릭 오픈소스 프로메테우스
4주 차에서는 메트릭 오픈소스인 프로메테우스 오퍼레이터를 공부했습니다. 프로메테우스 오퍼레이터를 이용하여 메트릭 수집방법과 알림기능 실습했습니다. 이번 주차에는 github copilot도움을
malwareanalysis.tistory.com
프로메테우스는 k8s에 메트릭값을 수집하고 쿼리문을 통해 조회 가능한 모니터링 솔루션이고 무료이다.
프로메테우스는 조회하면 간단하게 나타나서 조회가 어렵고 시각화도 별로여서 시각화 부분은 grafana와 연동하여 사용한다.
이번 포스팅은 k8s에서 자주 사용하는 프로메테우스와 그라파나를 작성해보겠습니다.
실습
설치
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.27.2 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
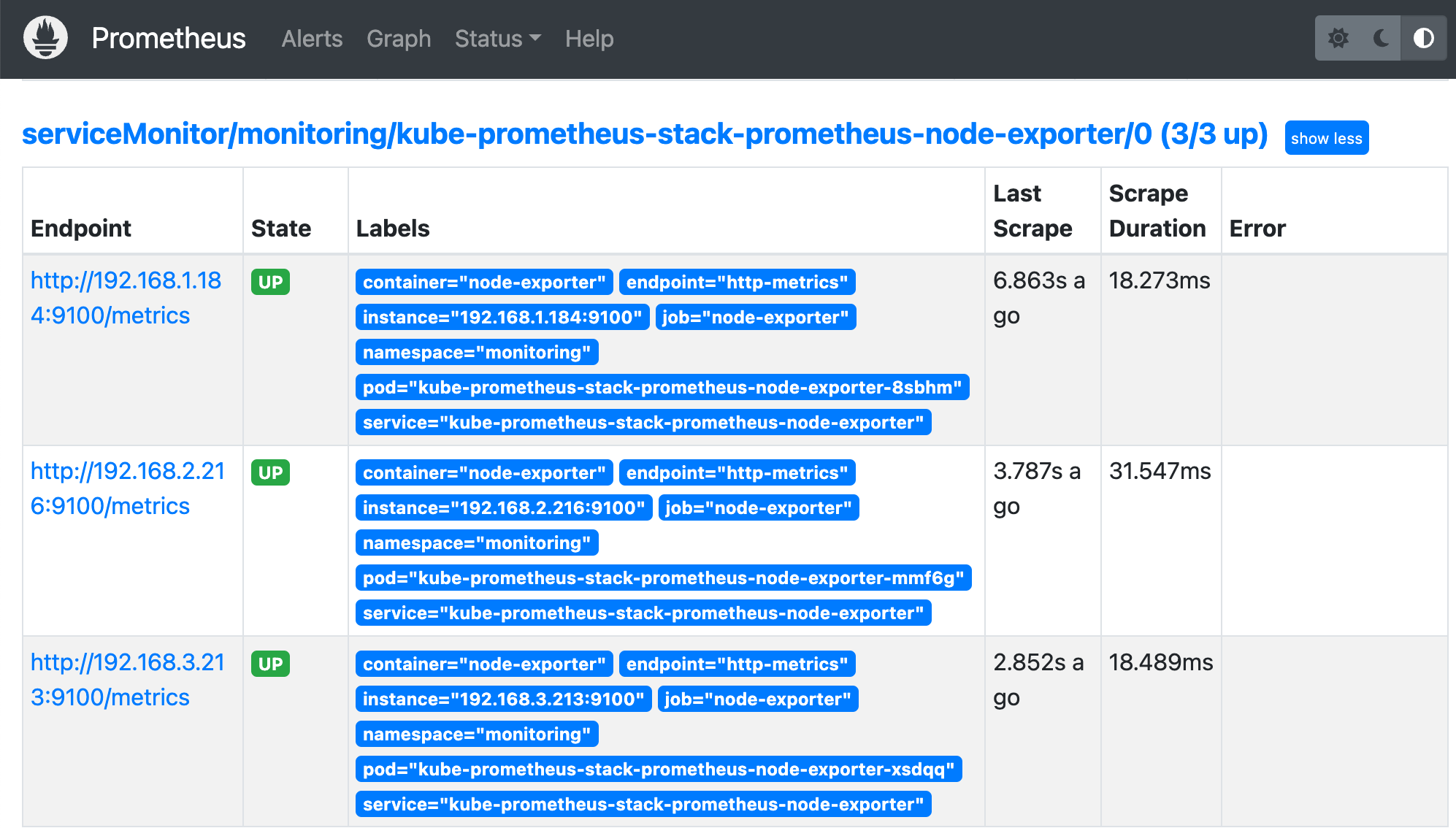
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring결과 확인

기본 사용법
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics
# 아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics접속하기
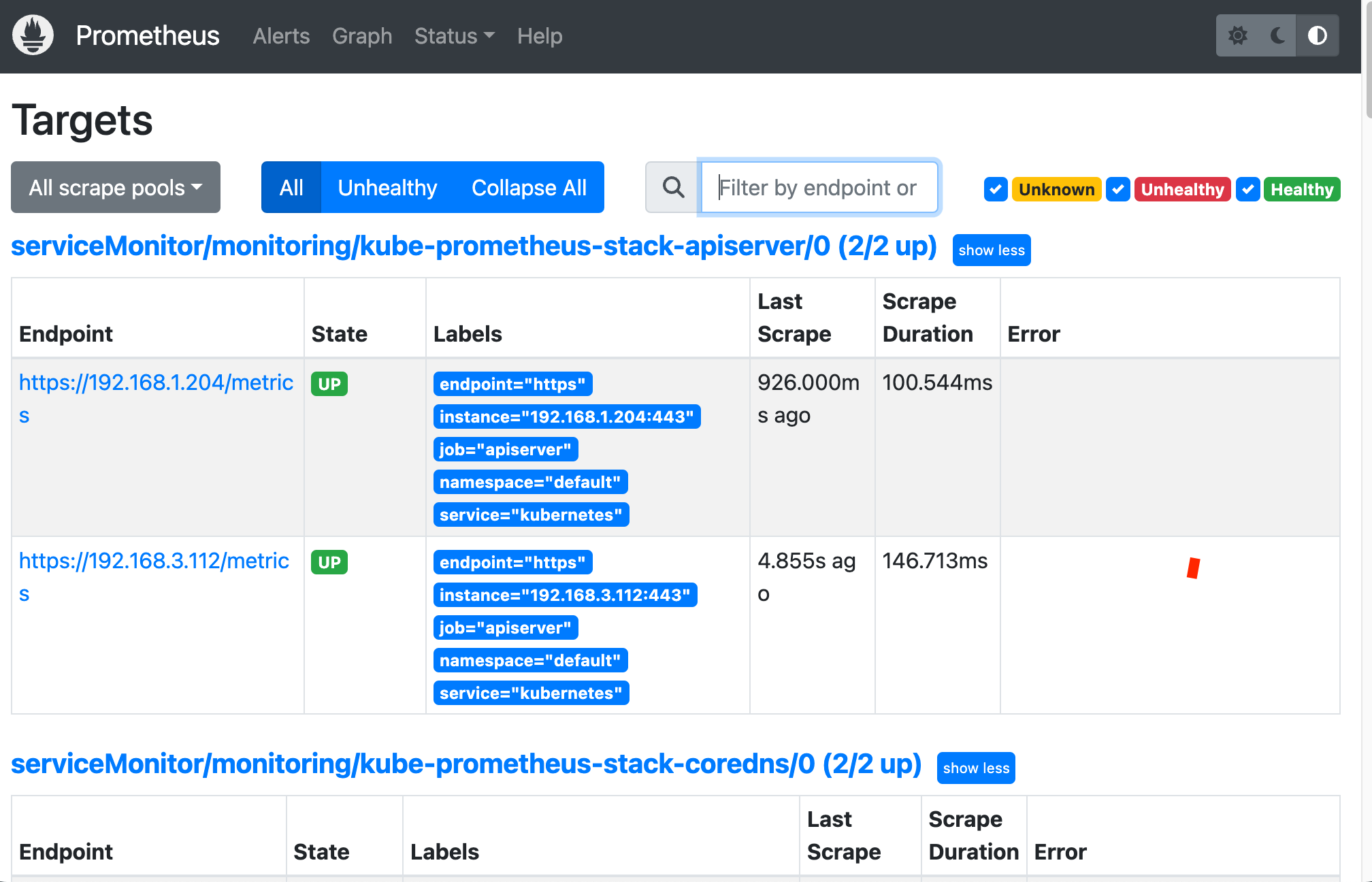
타겟(모니터링한 서버 확인하기)
api 서버
노드 상태를 확인해주는 node-exporter
쿼리로 그래프 확인해보기
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain"
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)기타내용
- 쿼리 입력 옵션
- Use local time : 출력 시간을 로컬 타임으로 변경
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
- Enable linter : ?
- 프로메테우스 설정(Configuration) 확인 : Status → Runtime & Build Information 클릭
- Storage retention : 5d or 10GiB → 메트릭 저장 기간이 5일 경과 혹은 10GiB 이상 시 오래된 것부터 삭제 ⇒ helm 파라미터에서 수정 가능
- 프로메테우스 설정(Configuration) 확인 : Status → Command-Line Flags 클릭
- -log.level : info
- -storage.tsdb.retention.size : 10GiB
- -storage.tsdb.retention.time : 5d
- 프로메테우스 설정(Configuration) 확인 : Status → Configuration ⇒ “node-exporter” 검색
- job name 을 기준으로 scraping
**global**: scrape_interval: 15s # 메트릭 가져오는(scrape) 주기 scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃 evaluation_interval: 15s # alert 보낼지 말지 판단하는 주기 ... - **job_name**: serviceMonitor/monitoring/**kube-prometheus-stack-prometheus-node-exporter**/0 scrape_interval: 30s scrape_timeout: 10s **metrics_path**: /metrics **scheme**: http ... **kubernetes_sd_configs**: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영 - role: **endpoints** kubeconfig_file: "" follow_redirects: true enable_http2: true namespaces: own_namespace: false names: - monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
전체 메트릭 대상(Targets) 확인 : Status → Targets
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
- 현재 각 Target 클릭 시 메트릭 정보 확인 : 아래 예시
# serviceMonitor/monitoring/kube-prometheus-stack-kube-proxy/0 (3/3 up) 중 노드1에 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
curl -s http://192.168.1.216:10249/metrics | tail -n 5
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="4.194304e+06"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="1.6777216e+07"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="+Inf"} 1
rest_client_response_size_bytes_sum{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 626
rest_client_response_size_bytes_count{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 1
# serviceMonitor/monitoring/kube-prometheus-stack-api-server/0 (2/2 up) 중 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
>> 해당 IP주소는 어디인가요?, 왜 apiserver endpoint는 2개뿐인가요? , 아래 메트릭 수집이 되게 하기 위해서는 어떻게 하면 될까요?
curl -s https://192.168.1.53/metrics | tail -n 5
...
# 그외 다른 타켓의 Endpoint 로 접속 확인 가능 : 예시) 아래는 coredns 의 Endpoint 주소 (접속 주소는 실습 환경에 따라 다름)
curl -s http://192.168.1.75:9153/metrics | tail -n 5
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.79350016e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19- 프로메테우스 설정(Configuration) 확인 : Status → Service Discovery : 모든 endpoint 로 도달 가능 시 자동 발견!, 도달 규칙은 설정Configuration 파일에 정의
- 예) serviceMonitor/monitoring/kube-prometheus-stack-apiserver/0 경우 해당 address="192.168.1.53:443" 도달 가능 시 자동 발견됨
- 메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인
1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))
# 노드 메트릭
node 입력 후 자동 출력되는 메트릭 확인 후 선택
node_boot_time_seconds
# kube 메트릭
kube 입력 후 자동 출력되는 메트릭 확인 후 선택
그라파나 사용하기
설치
# 그라파나 버전 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- grafana-cli --version
grafana cli version 9.5.1
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"아이디 : admin
패스워드 : prom-operator
대시보드 설명
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Connections : 설정, 예) 데이터 소스 설정 등
- Administartor : 사용자, 조직, 플러그인 등 설정

데이터를 받아오는 서버 확인
Connections → Your connections : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인
# 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
해당 데이터 소스 접속 확인
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
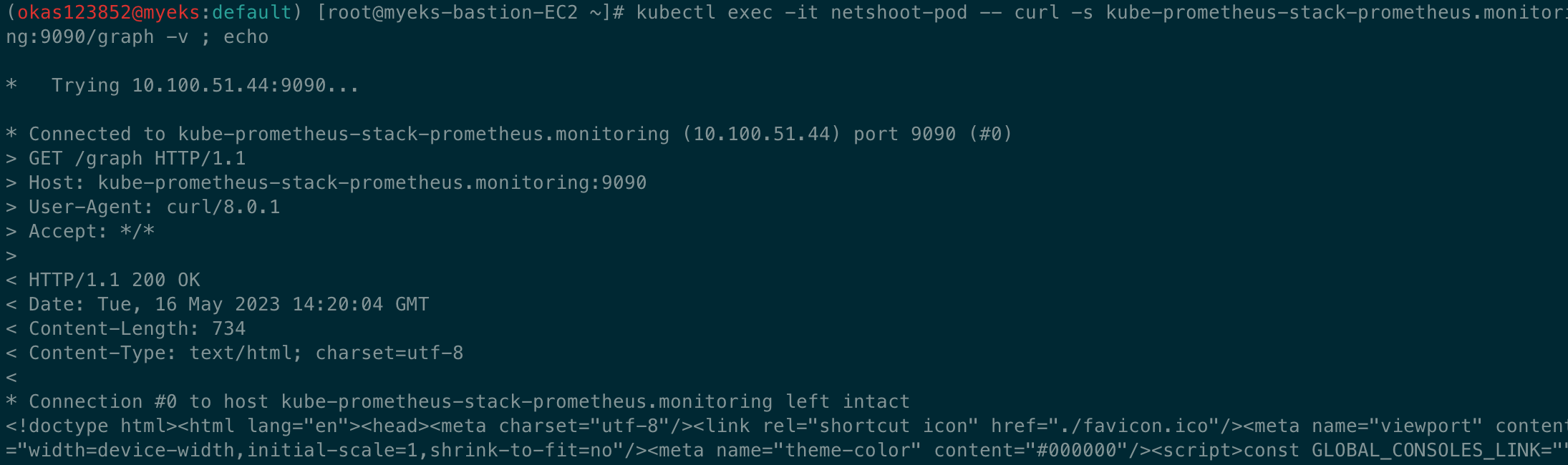
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
# 삭제
kubectl delete pod netshoot-pod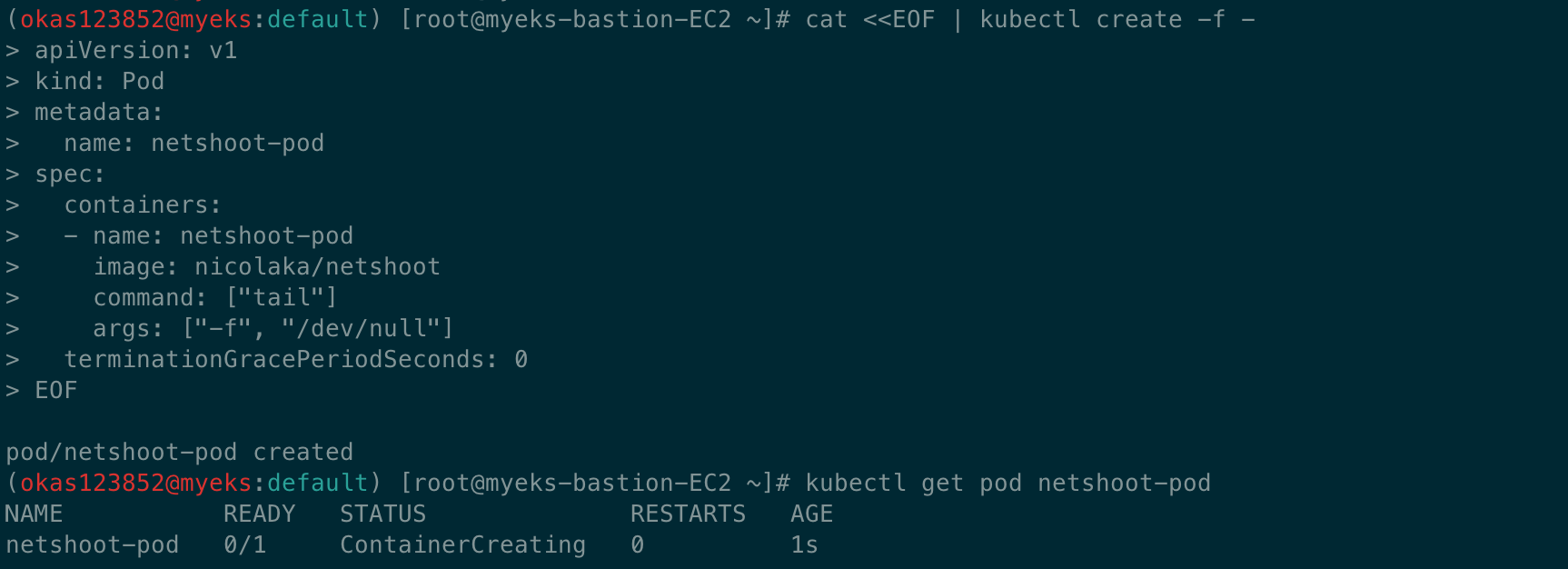
실습 - 공식 대시보드 가져오기
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
공식 대시보드 : https://grafana.com/orgs/imrtfm/dashboards
dotdc Dashboards | Grafana Labs
Data visualization & monitoring with support for Graphite, InfluxDB, Prometheus, Elasticsearch and many more databases
grafana.com
해당 링크에서 마음에드는 대시보드가 있다면 번호를 가져와 import 한다.
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 13770 or 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → New → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [**Node Exporter for Prometheus Dashboard based on 11074] 15172
- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → New → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

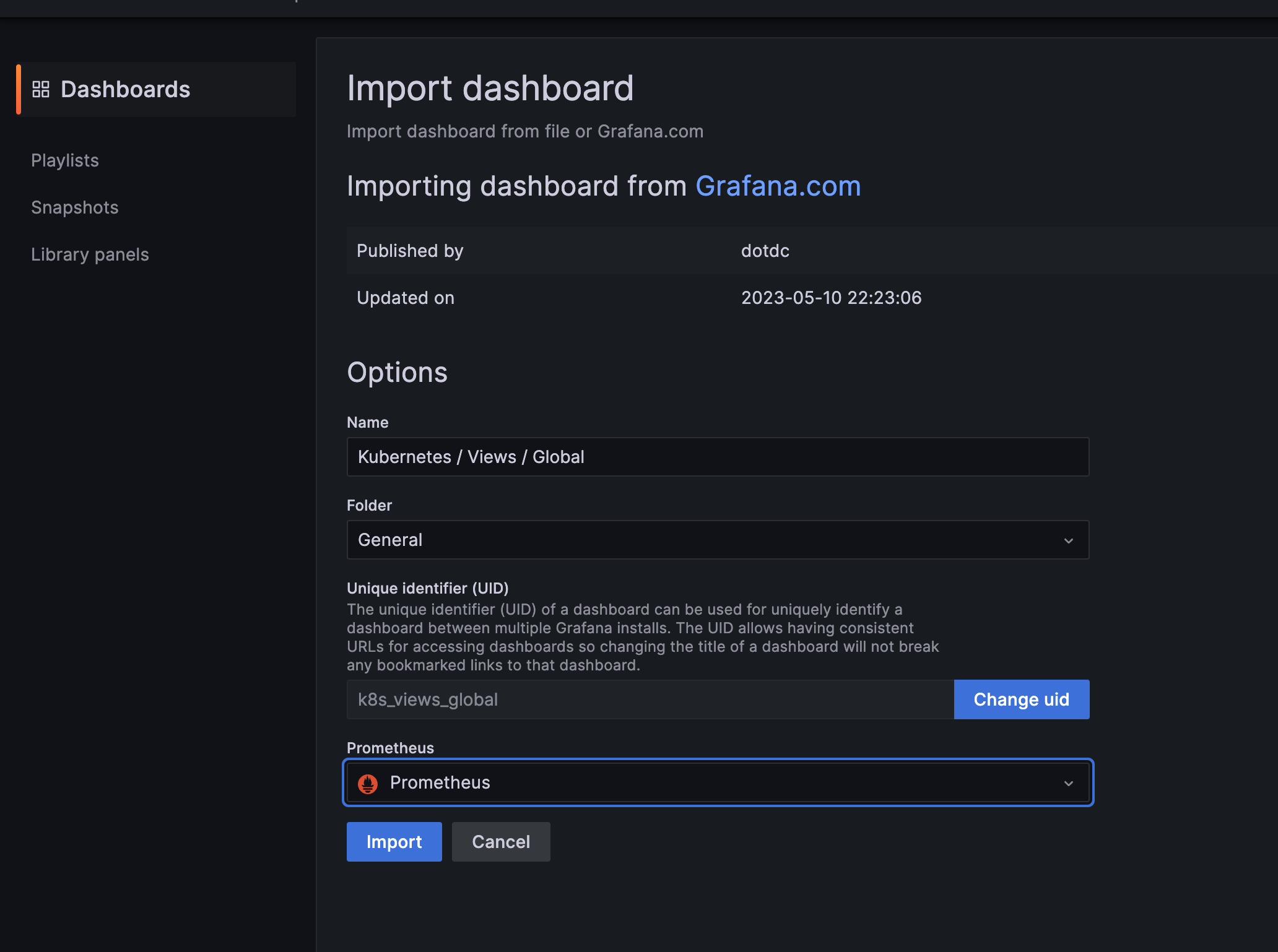
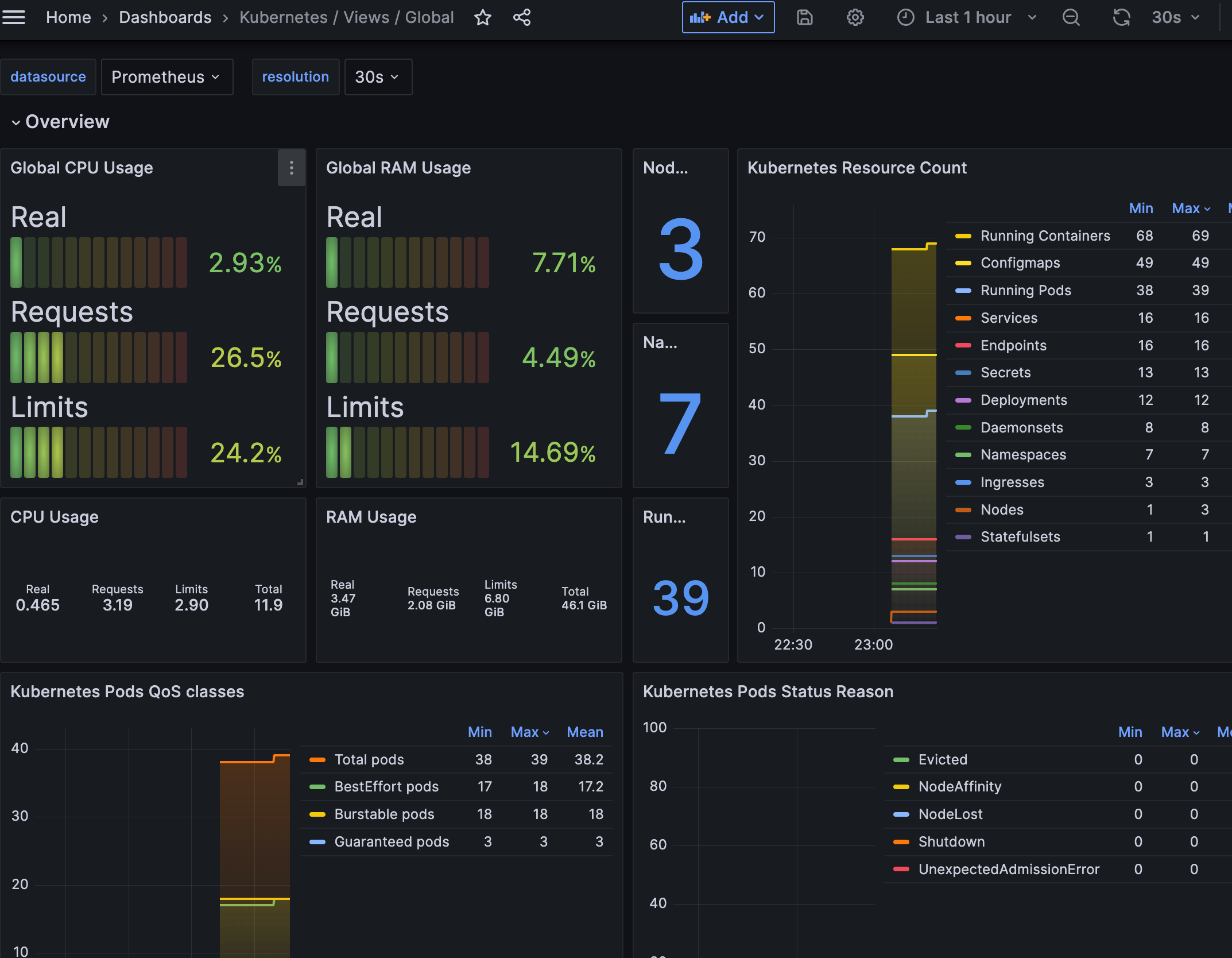
* EC2 CNI 대시보드 가져오기
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system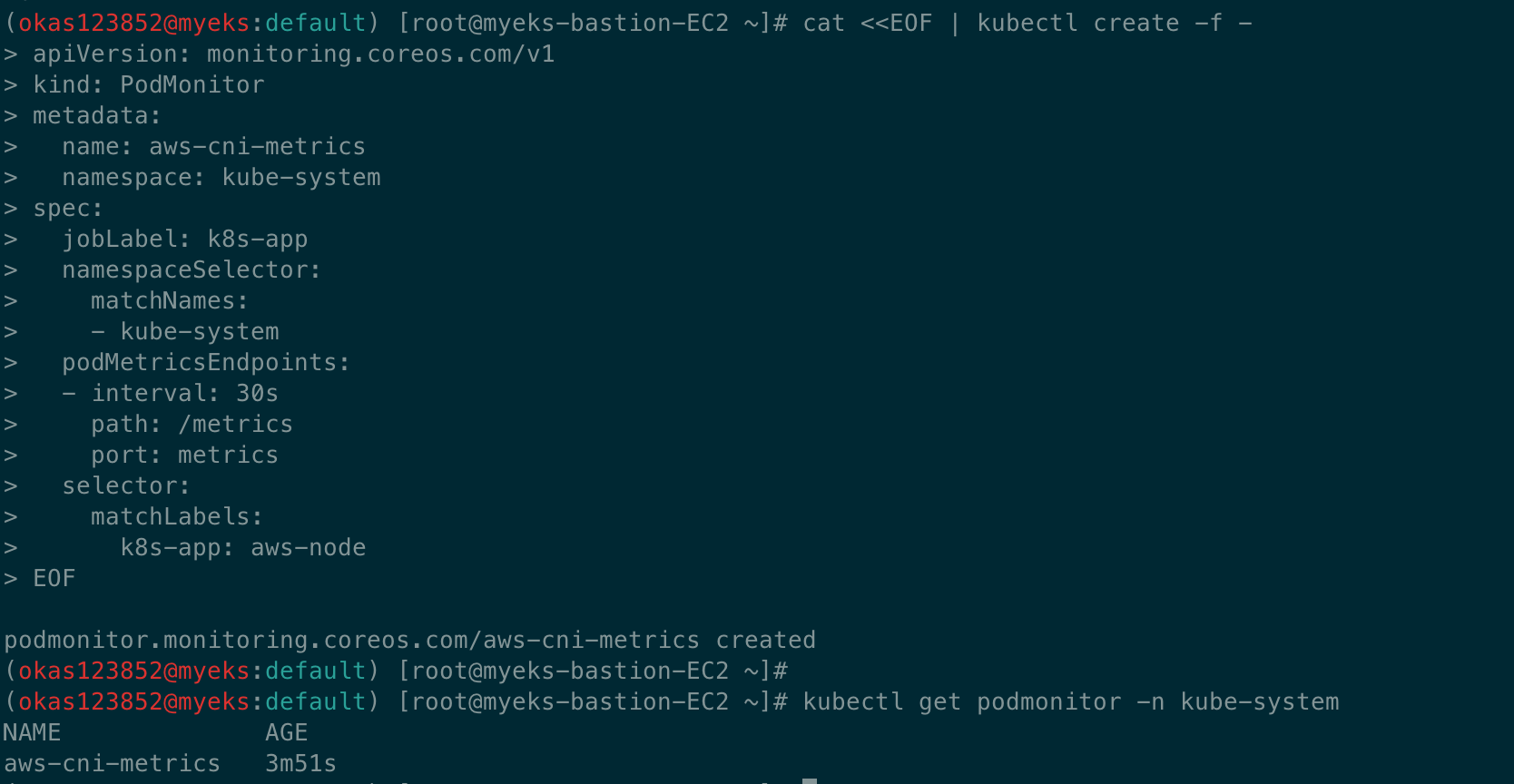
AWS CNI Metrics 16032 -> 링크
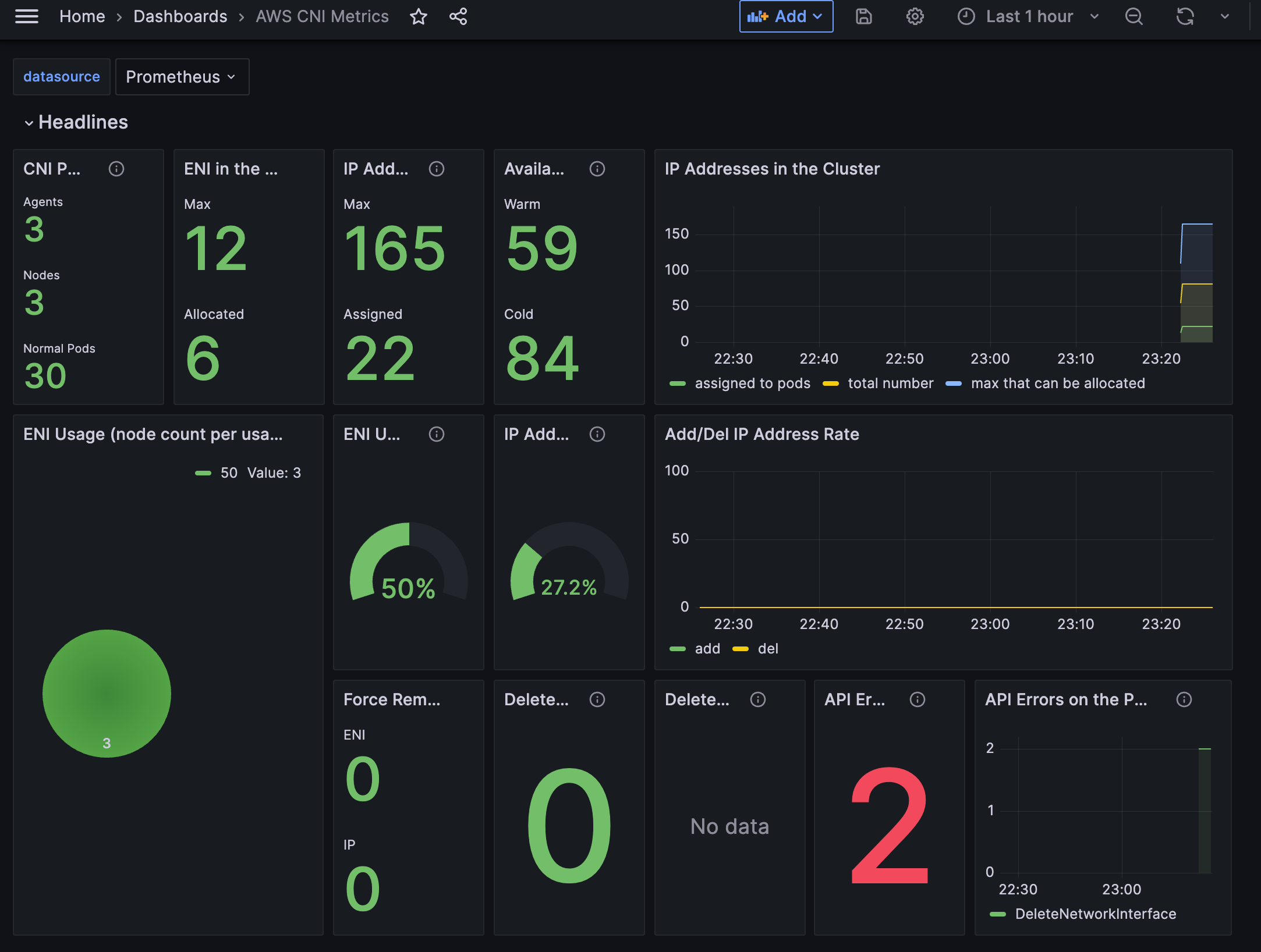
삭제
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com'클라우드 > AWS' 카테고리의 다른 글
| [AWS] EKS Autoscaling - 5주차 -실습환경 배포 (0) | 2023.05.23 |
|---|---|
| [AWS] EKS Autoscaling - 5주차 (1) | 2023.05.23 |
| [AWS] EKS monitoring - 4주차 -Metrics-server & kwatch & botkube (0) | 2023.05.18 |
| [AWS] EKS monitoring - 4주차 -Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs) (0) | 2023.05.18 |
| [AWS] EKS monitoring - AWS LB/ExternalDNS/EBS/EFS, kube-ops-view 설치 (0) | 2023.05.18 |


